12 the tidyverse
The tidyverse is an opinionated collection of R packages designed for data science - https://www.tidyverse.org/
R had its origins in S, a system designed for engineers at Bell Labs. This audience meant that R would be more accessible to those with programming backgrounds, more aimed at “developers” than users approaching data science from an applied or statistical perspective than one in programming. As the popularity of R increased, it would become more flexible and versatile for these power users, but there was less progress in making R accessible to and tailored for data scientists. To this day, “base-R” is, for most users, more challenging than SPSS or Stata. The tidyverse was born partly to address these issues (Peng 2018).
The tidyverse is a growing set of interconnected packages which share a common syntax; it can be seen as a dialect of R. More precisely,
…the tidyverse is a lucid collection of R packages offering data science solutions in the areas of data manipulation, exploration, and visualization that share a common design philosophy. It was created by R industry luminary Hadley Wickham, the chief scientist behind RStudio. R packages in the tidyverse are intended to make statisticians and data scientists more productive. Packages guide them through workflows that facilitate communication and result in reproducible work products. The tidyverse essentially focuses on the interconnections of the tools that make the workflow possible (Gutierrez 2018).
The workflow is one that you have seen here and in R4DS. In this 2017 slide, the main processes of data analysis are accompanied by the packages in the tidyverse. (As of 2019, there have been a few small changes in the packages associated with modeling). All of these are installed on your computer with install.packages(“tidyverse”), but only those in bold are loaded into memory when you issue the command library(tidyverse):
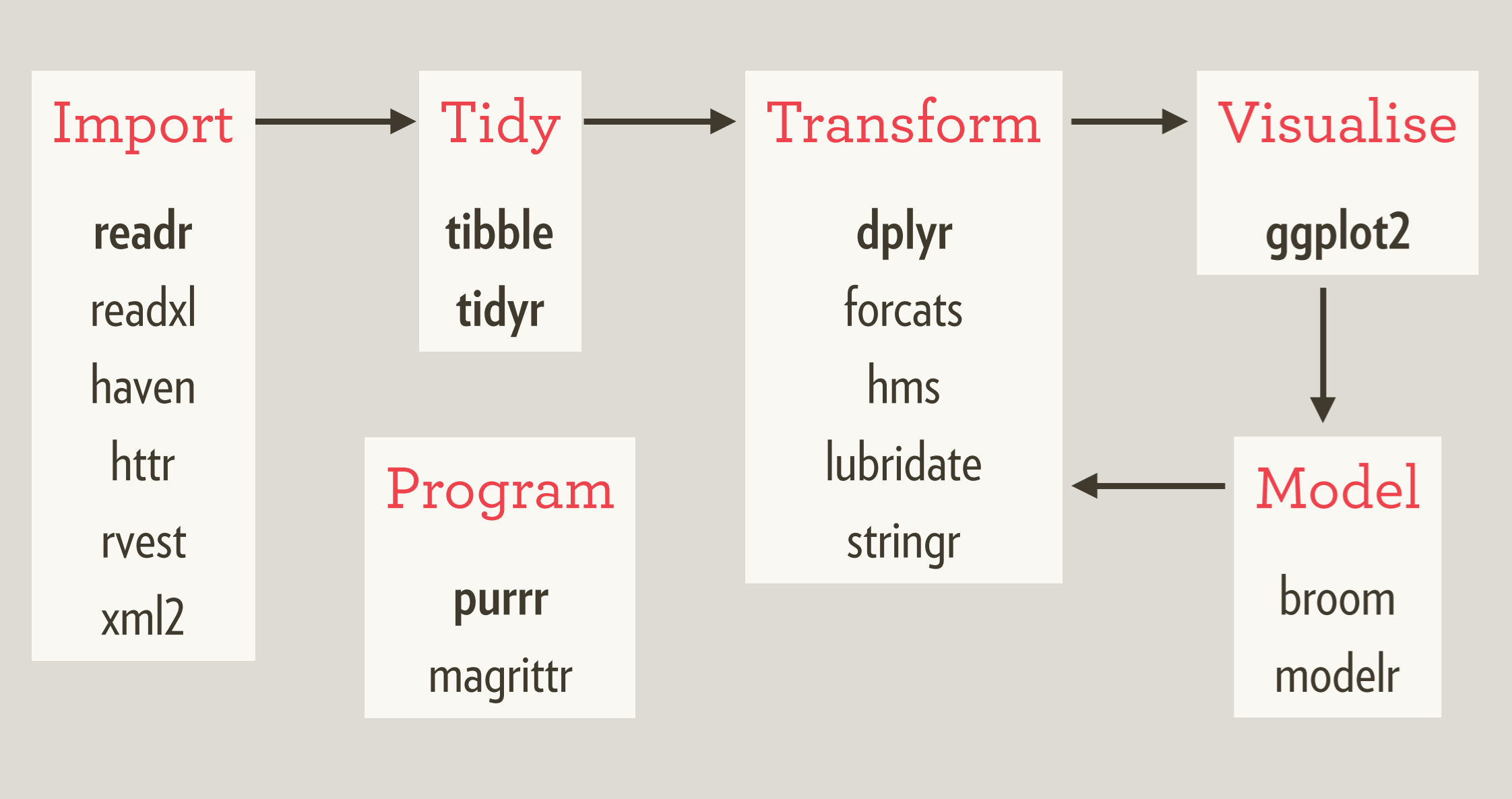
Fig 10.1: Schematic of the tidyverse. From Wickham’s 2017 rstudio:conf keynote
12.1 some simple principles
- search for tidyverse solutions. When you have a problem in your code, for example, “how do I compute the mean for different groups of a variable,” search for R mean groups tidyverse, not just R mean groups. This will get you in the habit of working with tidy solutions where they can be found.
library(tidyverse)
mtcars %>%
group_by(cyl) %>%
summarise(mean = mean(disp), n = n())(Another suggestion: Because R and the tidyverse are constantly evolving, consider looking at recent pages first. In your Google search bar, click on Tools -> Past year).
talk the talk. Recognize that %>% (the pipe) means then. Statements with pipes begin with data, may include queries (extract, combine, arrange), and finish with a command.
annotate your work. Assume that you will come back to it at a later date, while working on a different project, and use portions of your current code. Your R markdown documents should be a log. When you run in to a significant, challenging problem, don’t delete your mistakes, but ## comment them out.
library(gapminder)
b <- gapminder %>%
## when should you comment out an error
## instead of deleting it? for me, I'll
## comment out errors that took me a long time
## to solve, and/or that I'll learn from.
## Probably not here, in other words...
## filter(lifeExp) > 70 bad parens
filter(lifeExp > 70)work with tidy data. Make each row an observation, and each column a variable. Complex data sets, such as samples of text, become much more manageable when reduced to simple arrays.
write functions. If you repeat a section of code, rewrite it as a function. (We’ll come back to this later).
adhere to good coding style. Well-written code is reasonably parsimonious, readable, and easily debugged. There are a few style manuals for R, including one from Hadley, and this [Rchaeological Commentary] (https://cran.r-project.org/web/packages/rockchalk/vignettes/Rstyle.pdf).
but maintain perspective. Your need to solve problems (how to analyze x, etc.) should not take a back seat to your desire to write the best code. There is almost always a better way to do things. Strive reasonably to accomplish this, but be prepared to kludge.